Cet été, j’ai écrit et publié trois articles parlant des navigateurs internet :
- Une présentation générale
- Un historique allant des prémices à la standardisation du web
- L’ingénierie expliquant leur fonctionnement interne
Au départ, je pensais que mes recherches et la rédaction allaient juste m’amener à faire de la vulgarisation. Mais plus je travaillais dessus plus je devenais hyppé par cette technologie.
J’ai décidé de m’y plonger en créant la première pièce de mon moteur HTML baptisé Falcon.
Après avoir pris cette décision, il a fallu choisir un premier élément à développer.
Vous avez sûrement oublié leur fonctionnement, sauf si vous venez de lire mes articles ou si vous êtes devenus un fanboy des navigateurs grâce à moi. Voici un schéma résumant leur fonctionnement interne pour vous rafraîchir la mémoire :
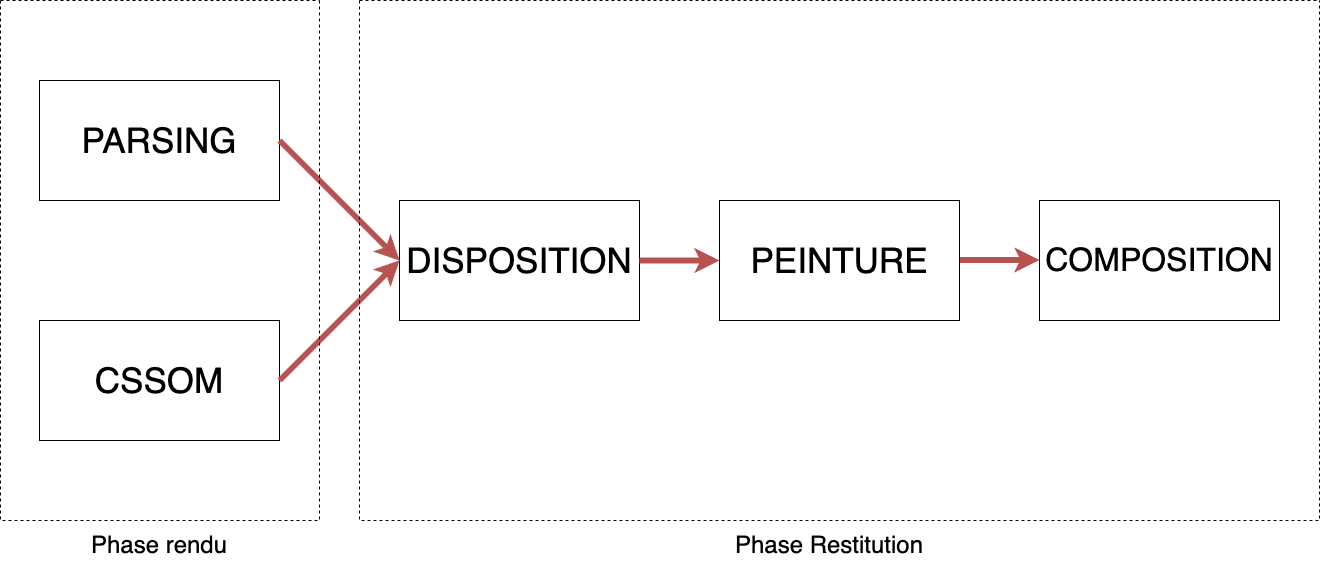
Résumé du fonctionnement navigateur internet
Pour rappel :
- Le Parsing permet d’analyser le html de la page et d’obtenir un arbre de données regroupant toutes les informations du html.
- Le CSSOM analyse le code css pour fabriquer un arbre le reliant au html.
- La Disposition fusionne les deux arbres obtenu pour créer un nouvel arbre avec toutes les informations.
- La Peinture détermine le placement de chaque élément en identifiant le rôle des pixels de l’écran concerné.
- La Composition va se charger de diviser le contenu à afficher en calques pour optimiser leur futur affichage.
J’ai décidé d’aller au plus simple en développant le parsing de mon moteur.
Comme le parsing identifie chaque élément composant une page html, l’identification de chaque tag a été la première feature développée.
Identification de la balise
Composition d’un tag
Voici un exemple de tag présent dans une page html :

Ce tag peut être subdivisé en 4 parties :
- <h1 class= ‘title’ style= ‘color :blue ;’> est la balise ouvrante.
- class=’title’ style=’color :blue ;’ sont les attributs de la balise.
- </h1> est la balise fermante.
- Hello World est le contenu du tag.
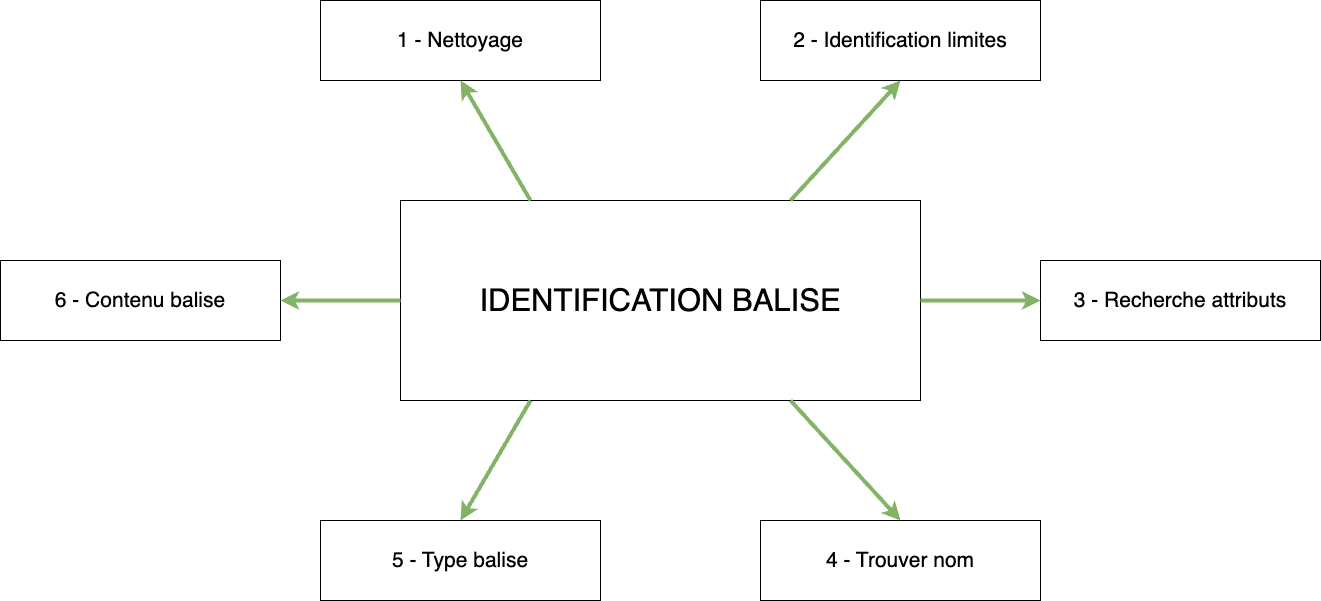
Pour cette partie d’identification, mon parseur exécute 6 étapes :
- Nettoyage du tag.
- Identification des limites du tag.
- Recherche des attributs du tag.
- Trouver le nom du tag.
- Indiquer le type du tag.
- Retourner le contenu du tag.
Nettoyage du tag
Avant de commencer l’identification, mon parseur doit nettoyer le texte contenant un ou plusieurs tags html pour ne pas parasiter le parsing. Il élimine :
- Les espaces avant le début des premiers caractères intéressants.
- Les caractères d’échappement comme « \n » ou « \r ».
- Les espaces inutiles après la balise fermante
- Les espaces en trop dans la balise ouvrante
Après cette purge, le parseur commence l’analyse.
Identifier limite tag
Pour pouvoir identifier toutes les parties du tag, il faut déterminer :
- La balise ouvrante
- La balise fermante
En identifiant ces deux parties, le programme pourra plus facilement trouver le contenu, les attributs….
Le parseur commence par rechercher la balise ouvrante. Elle va chercher la chaîne de caractère commençant par « < » se terminant par « > ». Vous obtenez ainsi la première balise ouvrante de votre tag.
A partir de cette information, le parseur va calculer la balise fermante:
- Elle va prendre le nom de la balise.
- Elle génère l’élément recherché sous la forme </nomdelabalise>.
Pour rappel certaines balises comme html a p… possèdent des balises fermantes tandis que les balises meta input… n’en ont pas. En étudiant le texte à parser, le parseur va rechercher la balise fermante précédemment calculée. Si elle la trouve, il la retournera quand on lui demandera sinon il renverra un résultat null.
Identification des attributs
Les attributs de la balise ouvrante ajoutent des détails pour le navigateur. Elles peuvent par exemple ajouter du code css, lui attribuer un id ou une classe… Un tag html peut se composer de plusieurs attributs html.
Si on reprend le début d’une balise, on a:
![]()
La liste des attributs d’une balise se trouve entre le nom du tag et « > ». Il suffit de la récupérer cette chaîne de caractère. On obtient la liste de tous les attributs séparés par un espace.
Un attribut se trouve sous cette forme :

A gauche de l’égalité se trouve le type de l’attribut tandis qu’à droite se trouve sa valeur. Le type de l’attribut fait partie d’une liste normée. Le parseur doit donc reconnaître le type puis lui attacher sa valeur.
Attention, certains attributs n’ont pas besoin de valeur. Par exemple l’attribut « hidden » se suffit à lui-même.
Nom de la balise
Pour déterminer le nom de la balise, il y a deux scénarios :
- sans attribut html
- avec attribut html
Sans attribut html

Pour ce cas d’usage, il suffit de retirer < et > de la balise ouvrante et on obtient le nom de la balise.
Avec attribut html
![]()
Dans ce scénario, il suffit de prendre la chaîne de caractère entre le < et le premier espace précédant la liste des attributs.
Type balise
Cette balise peut se classer en deux catégories :
- Balise fermante
- Balise non fermante
Pour pouvoir le déterminer, il suffit de voir si le parseur a précédemment identifié une balise fermante.
N.B : je pense supprimer cette propriété, car son utilité est sujet à caution.
Recherche contenu
Pour finir, le parseur doit retourner le contenu de la balise. Il correspond au texte se trouvant entre la balise ouvrante et la balise fermante. Bien sûr en cas d’abscence de balise fermante, elle ne possède pas de contenu.
Pour le calculer, il faut prendre le tag dans son ensemble, supprimer la balise ouvrante et la balise fermante pour obtenir le contenu.
Pour résumer
Pour ceux que j’ai perdu, je vous propose ce schéma résumant comment fonctionne la phase d’identification
Dans cette partie, on a vu comment parser un simple tag. Cependant comment on fait pour parser l’ensemble des éléments d’une page html.
La gestion des tags enfants
Forme page html
Après avoir compris l’importance de l’identification du tag, prenons le temps d’analyser une simple page html.

- Tout d’abord premier tag de la page html a deux tags enfants :
- Head
- Body
- Le tag head a pour parent le tag html et quatre tags enfants :
- Deux tags meta
- Un tag title
- Un tag link
Le tag body a comme tag enfant un tag div qui lui-même a deux tags p enfants.
Après avoir analysé cette page html, on comprend que le contenu des tags se trouvant entre la balise ouvrante et la balise fermante peut soit contenir du texte ou soit d’autres tags.
En partant de ce constat, le programme a dû être conçu pour pouvoir analyser et parser le contenu de chaque tag.
Scénarios html à traiter
- Le contenu des tags à parser peut se présenter sous trois formats :
- Première forme : un tag parent possède plusieurs enfants, mais pas de petits enfants comme le tag head possèdant quatre enfants et aucun de petit enfant.
- Deuxième forme : un tag parent possède un enfant et un petit enfant. Par exemple le premier tag p possède comme enfant le tag span qui lui-même a pour enfant le tag a.
- Troisième forme : un tag parent a plusieurs enfants qui ont eux aussi leurs propres tags enfants. Dans notre exemple, la div possède deux tags p dont l’un a une descendance.
Il est temps de se pencher sur le traitement de ses formes par le parseur.
Recherche du bon parseur
Quand le programme rencontre un contenu à analyser, il doit choisir le bon parseur. Pour chaque tag, un parseur ayant ses propres règles a été développé.
-
- Comment cette partie s’exécute t’elle ?
- Le programme recherche le premier tag dans l’extrait qu’elle doit traiter.
- Elle recherche le parseur correspondant.
- On ajoute le parseur trouvé à la liste des parseurs que le programme va renvoyer à l’appelant.
- Elle supprime le html du tag traité dans le texte à analyser.
- Deux possibilités : 5a : Il n’a plus de html à traiter donc le programme de cette partie s’arrête et renvoie la liste des parseurs déjà trouvés. 5b : il reste du html donc le programme va boucler de nouveaux sur les étapes 1 2 3 4 5b jusqu’à ne plus avoir de html à traiter.
Si on prend les trois exemples précédemment évoqués :
- Forme 1 : le programme renverra pour le contenu du tag head, deux parseurs meta, un parseur title et un parseur link.
- Forme 2 : le programme renverra pour le contenu du premier tag p, un parseur span.
- Forme 3 : le programme renverra pour le contenu du tag div, deux parseurs p.
Parsing enfants
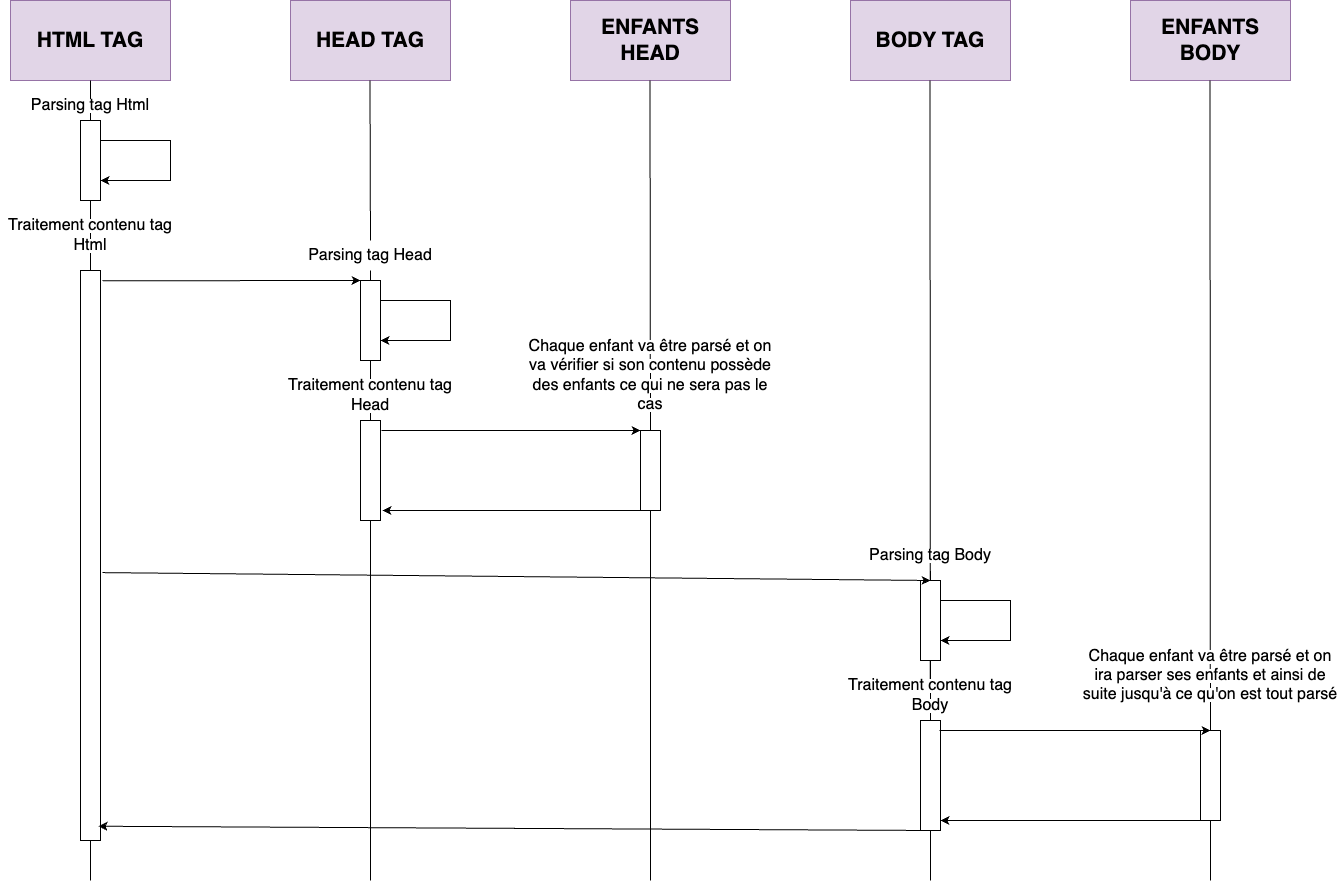
Après avoir récupéré les bons parseurs, le programme va se mettre à parser les enfants en 3 étapes :
- On nettoie le html à parser comme expliqué dans la partie sur l’identification.
- Le parseur trouvé précédemment parse le html lui correspondant.
- On supprime le html qui vient d’être parsé.
Ces 3 étapes vont continuer jusqu’à ce qu’il n’y ait plus de html à parser.
Traitement arbre
Pour le moment, le programme peut uniquement traiter les enfants. Si on prend l’exemple de la page html juste au-dessus, il va juste parser les balises head et body, mais n’ira pas s’occuper des balises meta, div….
Pour répondre à cette problématique, la récursivité a été mise en place.
Quand on parse un enfant, on va aussi voir si cet enfant a ses propres enfants, deux situations peuvent se passer :
-
-
- Aucun enfant trouvé, on s’arrête là.
- N enfant(s) trouvé(s), le parseur va aussi traiter se(s) enfant(s). Le programme bouclera jusqu’à ce qu’il n’y ait plus de descendance à parser.
-
Grâce à la récursivité, le programme pourra traiter une page entière. Cependant, ce n’est pas la solution la plus optimisée.
Pour résumer
Pour ceux que j’ai perdus, je vous propose ce schéma résumant comment fonctionne la gestion des tags enfants.
Je viens de vous présenter comment mon programme arrive à parser une page internet. Il fonctionne bien. Pour l’instant, les résultats obtenus montrent que l’outil fonctionne bien. Cependant il est loin d’être terminé, par exemple, il ne connaît pas toutes les balises et les attributs existants. Il ne peut pas parser toutes les pages. On ne peut pas le considérer comme opérationnel. Je vais donc vous parler des prochaines étapes de ce projet pour le rendre utilisable.
Avenir de Falcon
Balises et attributs inconnus
Pour pouvoir être utilisé dans les conditions réels, ce programme doit connaître toutes les balises et attributs existants.
En me basant sur la documentation du site Mozilla, je pourrai lister les balises et attributs manquant et développer leurs parsers. Mais je vois deux problèmes à cette façon de faire :
-
-
- Intégrer tous les tags et les attributs prendra du temps en étant long et fastidieux.
- Si on se base sur la loi de Paretto, on peut dire que 20% des balises et des attributs constituent 80% du web. Si on admet que cette loi se vérifie dans ce contexte, je devrai me concentrer sur ceux qui sont réellement les plus utilisés.
Pour éviter ces écueils, une autre solution se dessine. Je crée un webscrapper où j’incorpore mon programme. Ce nouveau produit se mettra à parser des pages Web et remontera les tags et les attributs qu’il ne connaît pas. Je n’aurai plus qu’à les incorporer dans mon programme en développant les parsers correspondant.
Pour préparer cette solution, il y a deux choses à faire :
- Il faut un système d’exception pour remonter facilement les éléments qu’il n’arrive pas à parser. Heureusement, je l’ai développé il y a quelques semaines.
- Créer un système de logs où tous les éléments non parsables seront notifiés. Ensuite, le comportement du programme devra être modifié. Actuellement à la première erreur, il s’arrête de fonctionner. A place, il marquera dans les logs l’élément inconnu et continuera à parser le reste de la page. Ainsi à la fin de son exécution, j’aurai une liste d’éléments à intégrer.
-
Performance
Importance de la performance
Comme dit dans mes précédents articles, la vitesse d’exécution d’un navigateur internet est très importante. La partie parsing de mon moteur doit donc être la plus rapide possible. Après avoir permis à mon programme de pouvoir parser la majorité des pages web, il faut améliorer les performances.
Mesures
Tout d’abord, il faut que je puisse ajouter des mesures pour connaître son temps d’exécution et identifier les parties à améliorer.
Récursivité
Pour la gestion de l’arbre, la récursivité a été mise en place pour pouvoir parser une page entière. La récursivité n’est pas forcément la meilleure solution à cause de sa consommation mémoire. Pour le moment, aucun problème n’a été rencontré sur ce sujet là. Mais je serai peut-être amené à modifier cette partie pour améliorer les performances.
Répétitions
Plusieurs tâches identiques se répètent pendant le workflow. Par exemple, à plusieurs endroits le programme doit connaître la balise ouvrante et fermante du tag. Il les calcule à chaque fois. Pour un programme lambda, refaire cette tâche ne poserait aucun problème. Pour un programme où la rapidité devient la règle ce n’est pas la même chose. Il faudra peut-être modifier le workflow pour calculer les données nécessaires et les rendre accessibles au reste du programme.
Réécrire dans un autre langage
La première version de ce programme a été faite en C# un langage haut niveau. Pour gagner de la vitesse d’exécution, je serai peut-être amené à le réécrire dans un langage bas niveau comme :
-
-
- Go
- C++
- Rust
-
En le réécrivant, je pourrai obtenir :
-
-
- Une meilleure performance
- Un point de comparaison entre mon programme « haut niveau » et mon programme « bas niveau ».
-
Continuer le moteur html
Un moteur html comme on l’a vu dans les anciens articles, n’est pas constitué uniquement par un parseur. La création d’un CSSOM constituera la prochaine brique développée de Falcon.
Merci d’avoir lu cet article. J’espère ne pas avoir perdu beaucoup de monde. J’ai voulu vous montrer les deux principales features de mon programme :
-
-
- L’identification des enfants
- Le traitement de l’arbre formé par les tags de la page html
-
Si vous voulez voir le code voici le dépôt github. Prenez-le, clonez-le, faites un fork si vous le désirez. Si vous avez des améliorations à proposer ou des questions à poser, servez-vous des commentaires de ce blog ou du post LinkedIn présentant cet article.
De mon côté, un nouvel article paraîtra vous racontera le développement de ce programme et les décisions techniques prises pour faciliter sa création.


