Dans le précédent article, je vous ai présenté mon premier gros produit en cours de réalisation. Il est composé de plusieurs briques permettant de faire des simulations d’élections législatives avec un mode d’élections différentes comme la proportionnelle nationale ou une élection à un tour. Elles utiliseront les résultats des élections de 2022 et de 2024.
Comme expliqué précédemment, ce produit est composé de plusieurs briques ayant chacun un rôle particulier. Aujourd’hui, je vous propose de vous présenter la brique DataElectionsScenario. Son rôle est de rendre exploitable les données OpenData fournies par l’Etat Français. L’application va les utiliser pour créer des nouvelles données utilisables par les autres briques de notre produit.
Pour commencer, je vous propose de vous expliquer en détail comment les données OpenData sont traitées et transformées.
Les données : le nerf de la guerre.
Trouver les données
Pour ce projet, mais aussi pour cette application, j’ai besoin de trouver les données qui vont me permettre de faire les simulations. Sans elles, pas de données, pas d’applications pas de produits.
En France, l’état met à disposition plein de données publiques exploitables par n’importe qui, sur le site datagouv. Elles peuvent être au format xlsv ou json mais aussi être fournies par une API.
Dans mon cas, nous avons besoin des données des élections législatives 2022 et 2024. Pour cela, on peut les trouver à cette adresse :
Comme on peut le voir, pour le moment, j’ai simplement utilisé les données du 1er tour, car celles du 2nd me sont inutiles.
Exploiter les données
En écrivant cet article, je viens de me rendre compte que les données dont j’ai besoin peuvent être obtenu sous le format json. Comme au début de ce projet, je ne m’en étais pas rendu compte, je suis parti sur le format xlsx (format des excels de Microsoft).
En analysant les données de l’excel, on remarque que pour chaque ligne, on obtient ce schéma de données.
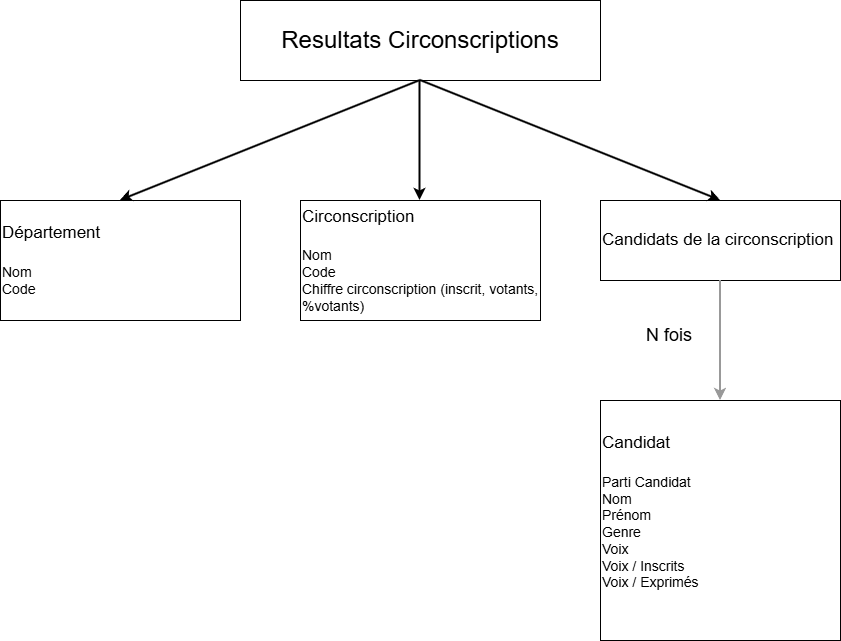
Imaginer les futures données
Maintenant, nous pouvons créer les données nécessaires aux autres applications de notre produit.
Les données créées par l’explication seront en format JSON.
À la fin, l’application dans le fichier JSON générera trois listes d’entités primordiales pour l’utilisation de la future API :
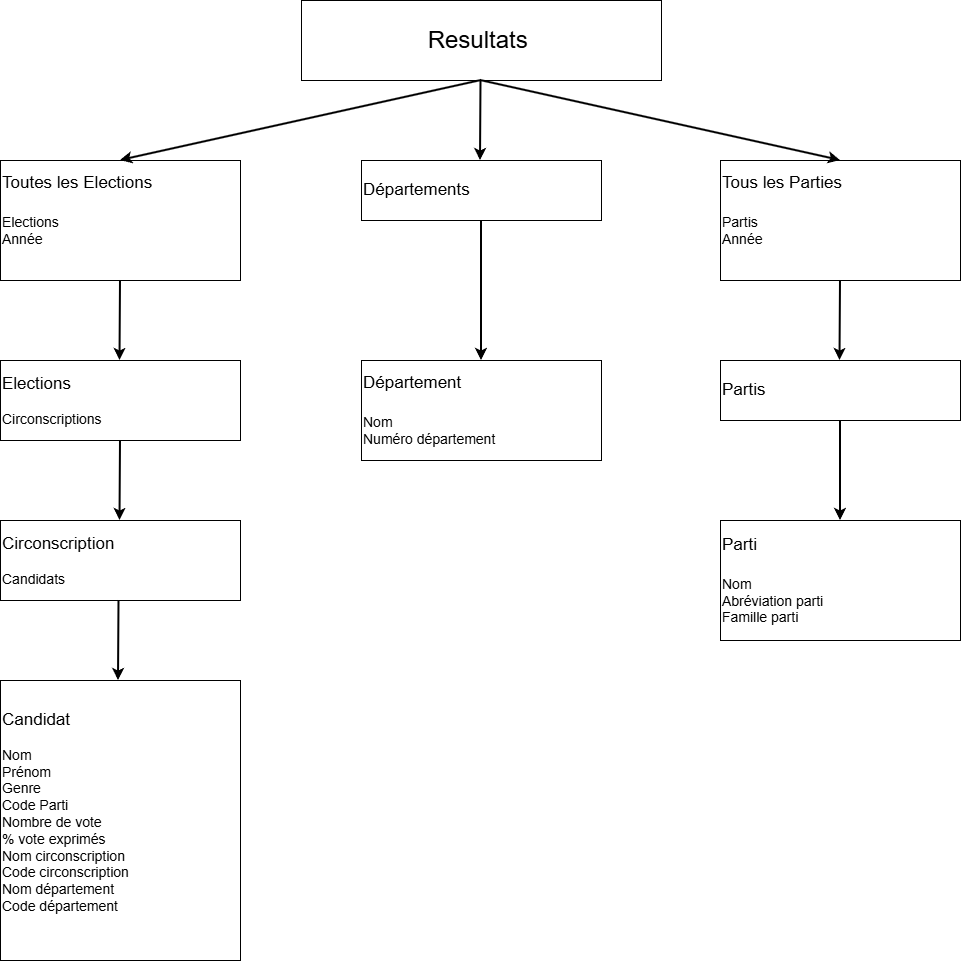
Toutes les données à part les partis politiques proviennent de l’excel dont on a parlé précédemment.
Comme on le voit, chaque élection est liée à une année. Dans notre cas, on traite uniquement les élections des années 2022 et 2024.
Chaque parti est lié à une famille Politique. Par exemple Horizons, Modem et Ensemble ! (Majorité présidentielle) font partis du Centre. Ne trouvant pas les données des partis dont j’avais besoin en OpenData, je me suis basé sur les données du site du ministre de l’Intérieur pour faire une classe qui les charge en mémoire.
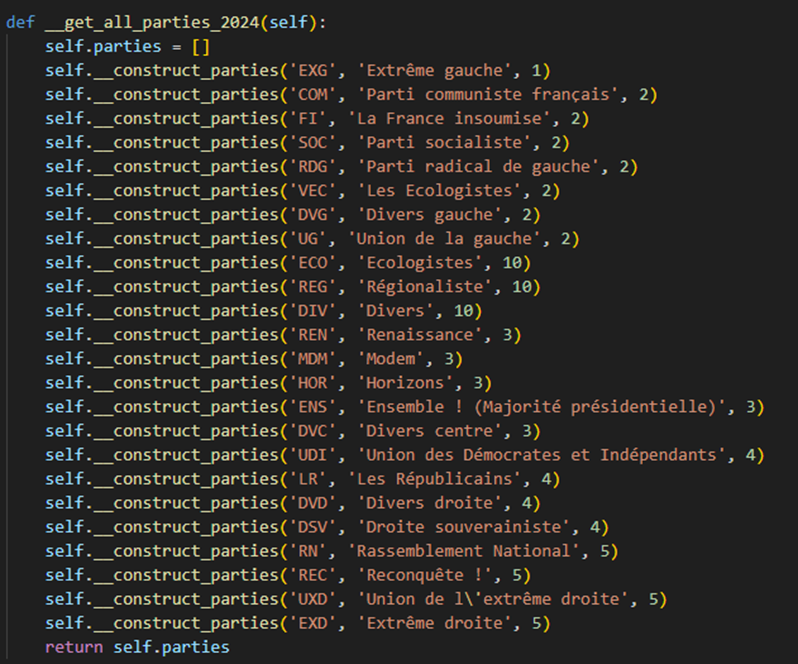
On sait quelles sont les données qu’on exploite pour avoir les données dont on aura besoin plus tard. Mais par quel moyen l’application DataElectionsScenario transforme les données de l’OpenData pour générer ses propres données.
Fonctionnement interne
Globalement, le fonctionnement de l’application peut être résumé par ce schéma :
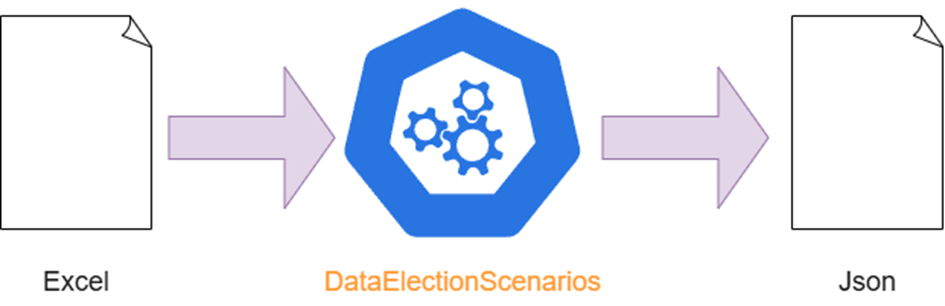
Tout se déroule en trois étapes :
- Récupération des données à partir d’un excel
- Transformation des données dans un nouveau format et un nouveau modèle
- Sauvegarde des nouvelles données dans un fichier Json
Récupération des données
Le programme charge en mémoire les excels grâce aux chemins indiqués dans le code. Pour l’instant, ils sont marqués en dur, mais demain ils pourraient être mis dans un fichier de configuration ou mis en argument dans la ligne de commande qui lance le programme.
Transformation des données
Pour ce nouveau modèle de données, il y a trois nouvelles entités à créer :
- Elections
- Départements
- Partis politiques
Elections
Comme expliqué juste avant, les Elections sont constituées d’une année d’élections et d’une liste de circonscriptions.
Chaque ligne correspond à une circonscription.
Tout d’abord voici les données issues d’une ligne de la lecture d’Excel.

En faisant cette opération dans chaque liste, on obtient les données de toutes les circonscriptions d’une élection.
Maintenant, on peut construire, les données élections en :
- Ajoutant l’année récupérée de la configuration et lié au fichier qu’on parse
- Ajoutant la liste des circonscriptions
Départements
Comme les départements sont immuables, on va juste les récupérer à partir d’un seul fichier excel à analyser.
Dans chaque fichier excel, les données liées aux départements se trouvent dans les deux premières colonnes. Pour construire une liste de tous les départements existants, on passe par ces étapes :
| Ordre | Etape |
| 1 | On parcourt ligne par ligne |
| 2 | On lit les deux premières colonnes |
| 3 | On construit le département |
| 4a | Si il n’existe pas dans la liste des départements qu’on constitue, on le rajoute |
| 4b | Si il existe dans la liste des départements qu’on constitute, on passe à l’étape 5 |
| 5 | S’il reste encore des lignes on repasse à l’étape 1 sinon le programme a terminé. |
La construction des données liées aux élections et des données liées aux départements nous oblige à parcourir plusieurs fois l’excel. Pour des soucis d’optimisation, on pourrait tout faire en même temps. Cependant, comme on ne cherche pas à optimiser l’exécution du programme, mais à avoir une exécution d’un programme facile à comprendre, l’optimisation n’a pas été mise en place.
Partis
Pour les partis politiques, ses objets sont construits en dur dans le programme. Pourquoi avoir choisi cette solution triviale ?
- Rapidité
- Flemme de chercher un document opendata regroupant les données dont j’avais besoin et de l’intégrer ensuite dans le workflow
- Besoin d’ajouter des données custom
Sauvegarder nouvelles données
Après avoir obtenu ces nouvelles données, le programme doit transformer cet ensemble d’objets pythons en un objet « Results_Elections » au format « Json » en passant par ces étapes :
| Ordre | Etapes |
| 1 | Transformer l’objet python Elections en objet Json |
| 2 | Transformer l’objet python Départements en objet Json |
| 3 | Transformer l’objet python Parties en objet Json |
| 4 | Construire un objet Results_Elections au format Json ayant pour attributs Elections, Departments et Partis. |
Après avoir obtenu ce nouvel objet json, le programme va créer un fichier json et écrire cet objet dedans. Ce nouveau fichier sera dans le path indiqué dans la ligne de commande d’exécution de ce programme.
Après avoir exploré quel était le fonctionnel de cette application, il serait intéressant de comprendre techniquement comment cette application fonctionne.
Et techniquement ?
Tous les choix techniques sont expliqués simplement dans ce tableau.
| Sujets | Explications |
| Langage | Ce programme a été codé en Python. Il est de plus en plus à la mode et peut être utilisé dans beaucoup de domaines (API, IA, Big Data…). |
| Type de programme | Le programme développé est une simple ligne de commande. |
| Librairie | Pour pouvoir manipuler les excels fourni par datagouv, j’utilise la librairie Panda. Elle fait bien le job et répond au critère du projet. J’aurai pu ne pas l’utiliser et coder ma propre librairie mais ayant un outil déjà fonctionnel et répondant déjà à mes critères, ca aurait été une perte de temps. |
| Pattern | J’ai utilisé le pattern Adapter détaillé ici. Je voulais absolument isoler les spécificités des formats xlsx (pour Excel) et Json aux parties concernées. Pour augmenter la maintenabilité d’un projet, il faut éviter de coupler trop son code. |
Concernant le python, je pourrai ajouter que personnellement ce n’est pas forcément un langage qui me fait vibrer. Le typage dynamique m’a provoqué des bugs bien relous à corriger. Je pourrai utiliser les annotations pour rendre mon code plus clair, mais ça ne m’empêcherait pas de faire encore des erreurs. Pour terminer, l’absence d’interface me désole aussi surtout quand on veut séparer proprement le code. Sur ce projet, cette architecture n’a pas été utilisée.
Même si ce projet a été terminé et je suis content de l’avoir fait, beaucoup de points à l’heure actuelle ne me plaisent pas et certains doivent être retravaillé. Avec du recul, je pourrai encore améliorer DataElectionsScenario. Prenons quelques minutes pour échanger dessus.
Améliorons DataElectionsScenario
Exécution
A l’heure actuelle pour le lancer, j’exécute cette commande python sur mon poste :
main.py chemin_où_nouveaux_fichiers_seront_stockés
Après, j’obtiens un fichier json que je déplace dans mon projet API pour pouvoir travailler dessus. Il permet aussi à mon API de démarrer.
Même si c’est fonctionnel, il faudra rendre dynamique cet ensemble surtout si j’héberge le tout dans le cloud.
Pour lancer ce workflow, je peux faire du serverless. Par exemple, si j’ajoute une nouvelle version de l’excel dans un dossier hébergé sur le système d’hébergement du fichier d’un cloud provider comme S3 pour AWS ou Azure Blob Storage sur Azure, une fonction serverless (AWS lambda pour AWS ou Azure Functions pour Azure) se déclenchera contenant le code de DataElectionsScenario pour générer le nouveau fichier json et le déposer pour alimenter notre API.
Rustine à supprimer
Pendant le développement, j’ai eu un petit souci avec certaines chaînes de caractères présentes dans l’excel.
La librairie « Panda » qui permet de lire les excels utilise « ‘ » comme séparateur. Quand un ensemble de mots a le « ‘ », mon programme n’arrivait plus à regrouper correctement toutes les données dans un tableau. Cette anomalie entraînera un échec de l’exécution du programme.

J’avais deux solutions :
- Faire un algo bien compliqué pour traiter ce « ‘ » se trouvant dans un groupe de mots.
- Comme les données changent rarement, on peut facilement voir les mots qui auront des « ‘ ». Comme ils sont peu à le posséder, on peut donc faire une rustine pour traiter ces cas.
Comme ce problème est bien localisé et limité, j’ai décidé pour le moment de prendre la solution 2. Ma priorité était d’avancer sur ce projet. J’ai donc modifié mon programme pour avant le traitement supprimer le « ‘ » pour le remettre après. Cependant, si un jour, je suis amené à intégrer plus de fichiers excels pouvant avoir plus de noms de famille incorporant « ‘ », il faudra que je développe un algorithme pour traiter cette erreur. Pourquoi ? La rustine décrite précédemment se complexifiera et la modifier deviendra de plus en plus compliqué avec un gros risque de régression.
Tout est question de curseur. Des fois mettre des rustines est la bonne solution, car le problème est minime et non prioritaire. En abuser ou les laisser indéfiniment à cet endroit pourra entraîner de gros problèmes.
Architecture logicielle bancale
Comment organiser son logiciel pour pouvoir répondre à ses besoins fonctionnels et faciliter sa maintenabilité ?
Voici l’architecture logicielle de mon projet. Je la trouve bancale voir nulle donc je vous demanderai de ne pas être trop dur dans votre jugement :
| Couche | Description |
| main.py | Point d’entrée du fichier |
| usecases | Représente les actions métiers que l’application permet de réaliser sans aucune dépendance avec des technologies extérieures |
| domain | Les entités métiers du projet |
| Infrastructure | Gère la partie technique de l’application ici : La manipulation des fichiers (lecture et écriture)Transformer les données issues des fichiers en données métiers |
| OpenDatas | Fichiers Excels |
Pourquoi je la trouve bancale
Cette architecture semble s’inspirer sur de l’architecture hexagonale sans en être vraiment.
J’avais deux choix pour architecturer cette application :
- Cette application ne possède pas de métiers. Elle convertit juste des données A liées à un excel en des données B liées à un Json. Une architecture ultra simple doit sans aucun lien avec l’architecture hexagonale doit être faite.
- Cette application possède bien un métier, car les données A et les données B sont une représentation de modèles métiers liée aux élections législatives. Je peux donc faire une application avec une architecture hexagonale appelée par une interface de commande.
Je n’ai jamais réussi à me départager et à y aller pleinement. L’architecture actuelle de mon application se rapproche de la solution 1. Cette architecture me frustre et je ne suis pas satisfait de cette partie.
Pourquoi ne pas s’occuper de ce problème ?
Ce projet à l’heure actuelle est terminé. J’ai peut-être encore quelques heures de travail dessus pour développer deux ou trois features.
Investir du temps sur une application qui ne sera pas appelé à être trop modifiée prochainement ne me semble pas être une bonne idée. De plus, c’est en faisant des erreurs comme celle-là qu’on apprend. Je sais qu’à l’avenir, je ne m’y prendrai différemment.
Conclusion
En lisant cet article, vous avez :
- vu quelles données utilisait la brique DataElectionsScenario pour pouvoir créer les siennes.
- compris son fonctionnement interne.
- analysé les briques techniques la composant.
- lu la liste les améliorations possibles pour cette brique.
Après avoir parlé des briques en développement ou des projets, je vous proposerai pour la prochaine fois plutôt du contenu sur le TDD utilisé pendant le développement de ce projet et du suivant.


