Navigateur Internet 3/3
Dans la trilogie des articles “Navigateur internet” nous avons vu :
- Le premier article nous a montré comment les navigateurs trouvaient le site internet à afficher et comment ils s’y connectaient de manière sécurisée ou non.
- Le second article a raconté l’histoire riche des navigateurs internet et de certaines caractéristiques de nos navigateurs modernes.
Dans ce dernier article, vous allez découvrir comment fonctionnent en interne les navigateurs et comment ils rendent les pages du site web téléchargées à partir des serveurs.
Fonctionnement interne navigateur
CPU/GPU
Pour comprendre le fonctionnement d’un navigateur, voyons comment il fonctionne et de quoi il a besoin pour tourner.
Toutes les tâches du navigateur nécessitant du calcul ont besoin de deux éléments de l’ordinateur ou du mobile :
- CPU
- GPU
Le navigateur utilise le CPU pour toutes les tâches nécessitant du calcul. Il peut gérer n’importe quelle tâche. Les vieux appareils, il n’avait qu’un seul exemplaire, tandis que les modernes en ont plusieurs. Dans le langage courant, on dit que l’appareil possède plusieurs cœurs. Le CPU de mon Mac possède 8 cœurs.
En navigant, pour afficher le contenu des pages web, beaucoup de calculs vont devoir être faits rapidement. Pour gagner en efficacité, le navigateur va utiliser le GPU. Cet élément est optimisé pour faire les calculs à hautes performances. Pour se faire, il va décomposer le calcul demandé en petits calculs. Ces derniers vont être faits par chaque élément du GPU en parallèle.
Thread
Comment s’exécutent les programmes à l’intérieur des navigateurs ? Comment une tâche est-elle lancée par le navigateur ? Il va le faire en utilisant les processus et les threads.
Un processus est créé à l’exécution d’un programme (ex : lancer une vidéo de Squeezie sur YouTube). Pour exécuter le programme de la façon la plus rapide et optimisée possible, on va lancer ces exécutions dans un ou plusieurs threads en fonction des ressources utilisées par le programme.
Un processus peut demander à l’ordinateur de créer un autre processus pour lancer un autre programme ou réaliser d’autres tâches. Pour communiquer, ces deux processus peuvent utiliser Inter Process Communication (IPC).
Processus
Plusieurs parties du navigateur avec des tâches bien définies fonctionnent ensemble pour permettre à l’utilisateur de pouvoir naviguer. Dans le navigateur Chrome, vous en avez plusieurs qui vont interagir entre eux, comme le montre ce schéma :
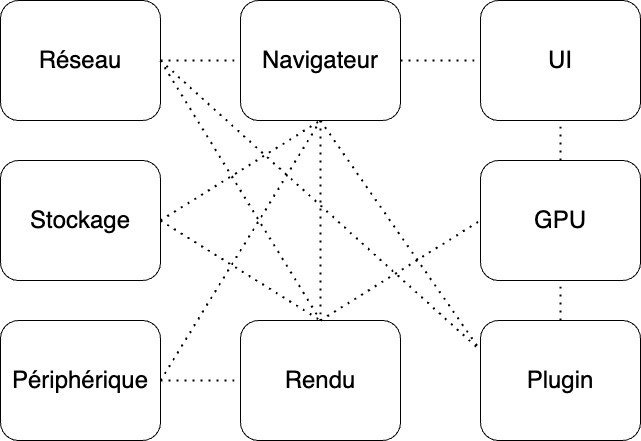
Comme expliqué juste après, chaque processus a un rôle bien particulier dans le fonctionnement d’un navigateur :
- Le processus Navigateur permet de gérer les appels aux autres processus nécessaires à la réalisation. On peut le comparer à un chef d’orchestre.
- Réseau va gérer tous les appels à des ressources présentes sur Internet. Par exemple, c’est lui qui va être appelé quand le navigateur doit contacter le serveur DNS pour la résolution de nom, comme vu dans la partie 1.
- Pour le stockage des cookies ou de données hors ligne nécessaires au fonctionnement d’un site, le processus Stockage entre en action.
- Pour gérer les interactions de la souris ou du clavier avec le navigateur, le processus Périphérique est appelé.
- Pour gérer les éléments graphiques du navigateur comme les fenêtres ou les checkbox, le processus UI entre en scène.
- Le processus Rendu gère l’affichage des sites internets à partir du code HTML/CSS/JS téléchargé par le navigateur.
- Le processus GPU va être utilisé pour faire tous les calculs nécessaires au « Rendu » mais aussi à « l’UI » ou à certains « Plugins ».
- Le processus Plugin va gérer tous les plugins installables sur le navigateur comme « AdBlock ».
À l’heure actuelle, les internautes exigent que leur navigateur soit le plus rapide possible. La partie « Rendu » se trouve être cruciale pour répondre à cette exigence. Pour cela, elle va transformer le HTML, le CSS et le JavaScript téléchargés, comme vu précédemment, en page web prête à être utilisée par un utilisateur. Comme vu dans la partie 1, elle se passe en deux phases :
- Parsing
- Restitution
Rendu
Parsing
Dom
Un des principaux buts du parsing est de créer un DOM à partir de la page html. Le DOM est une représentation de la page web et expose des APIs pour permettre au développeur de changer la structure de la page web grâce au Javascript.
Une page HTML est composée de balises entourant d’autres balises et du texte. Prenons en exemple cette page en HTML :
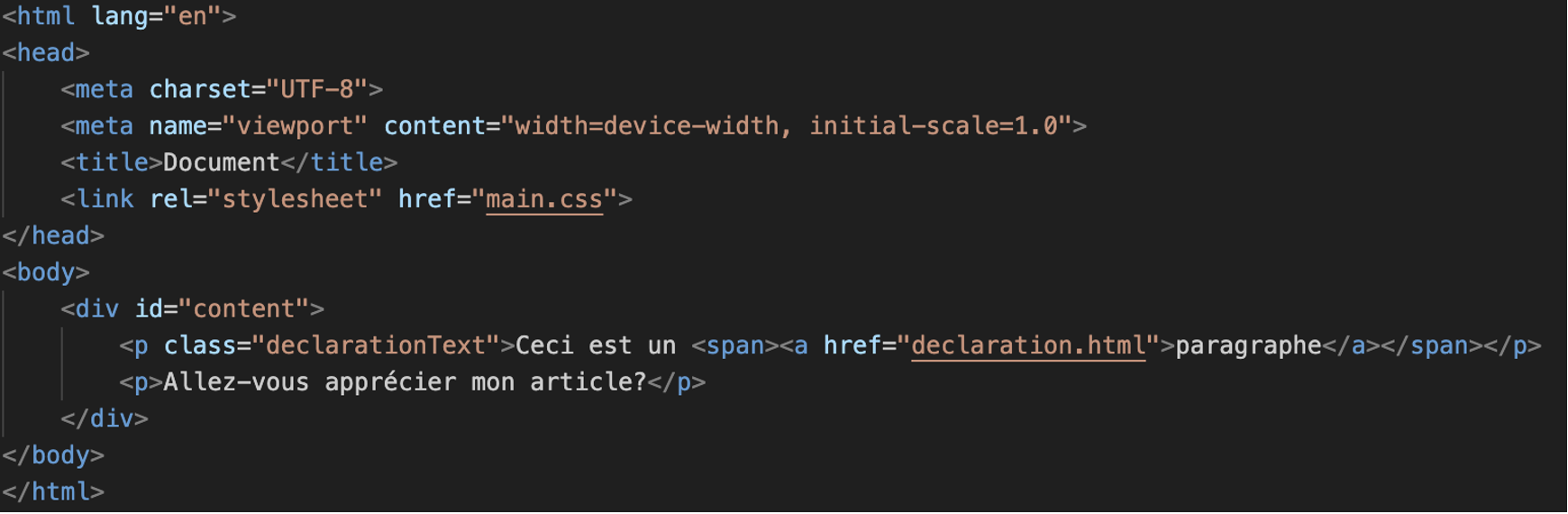
Voici le DOM obtenu :
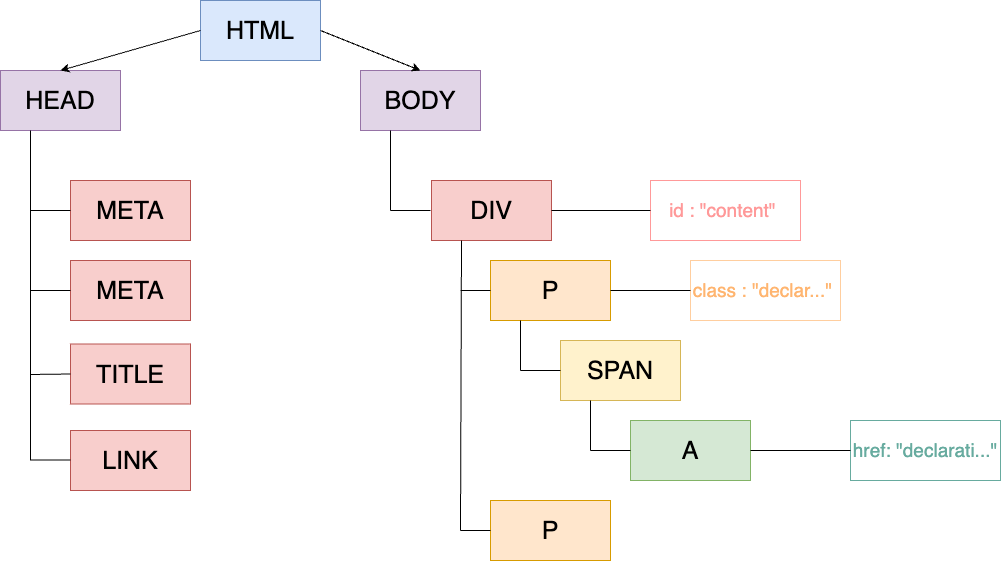
Dans cet arbre toutes les informations présentes dans le HTML s’y trouvent. Nous avons le nom des balises avec leurs attributs et le texte entouré par ses balises.
Pendant la phase de parsing, si du code JavaScript se trouve entre deux balises scripts ou dans un fichier annexe, tout s’arrête. Le moteur JavaScript prend le relais pour exécuter le code JavaScript pouvant manipuler le DOM.
Les balises « img » ou « link » sont reliées à des images ou à des fichiers css. Ils doivent être téléchargés pour pouvoir afficher correctement la page. Pour éviter de bloquer le parsing, Chrome, par exemple, fait en parallèle un scanner de préchargement lancé en parallèle.
CSSOM
Quand vous allez sur un site, la page web visitée possède une mise en forme pour être agréable à regarder et permettre d’avoir un parcours agréable. Le CSS indique au navigateur comment afficher le contenu (couleur de la police, sa taille ou emplacement d’un bloc…).
Pour avoir un affichage correct, le parsing va créer un CSSOM (CSS Object model).
Dans l’exemple ci-dessus, mon fichier HTML est lié au fichier CSS main.css :
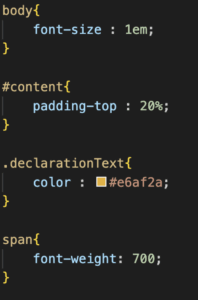
A partir de ce fichier css, on obtient l’arborescence CSSOM suivante :
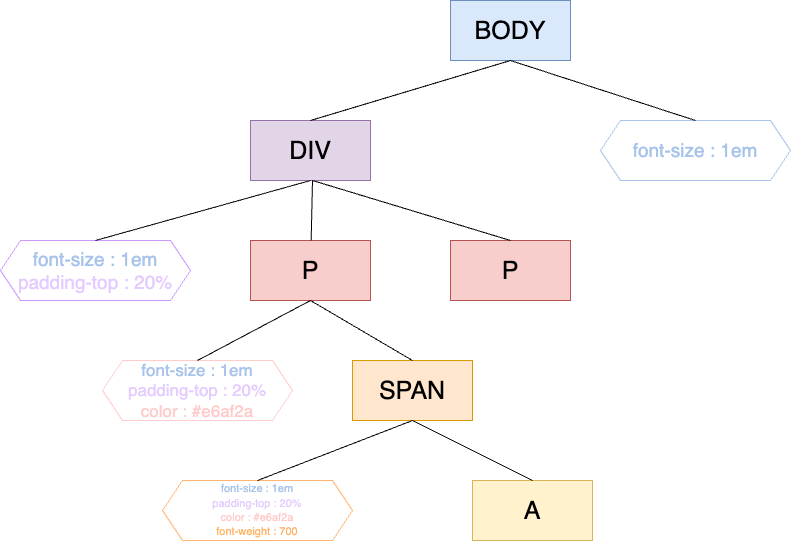
L’arbre ainsi obtenu contient bien toutes les informations liées au CSS. Comme on peut le voir, le CSS d’un nœud parent est hérité par les enfants. Par exemple, la balise Body a une propriété CSS qui sera aussi dans les balises enfants « Div » « P »…
Voilà maintenant la page a été parsé il faut l’afficher sur le navigateur et plusieurs étapes se passent.
Restitution
Disposition/Layout
Pendant la partie de parsing, on a obtenu le DOM et le CSSOM. Maintenant, un arbre de rendu va être calculé à partir de ces deux-là. Il contiendra tout le contenu visible du DOM et les données du style fourni par le CSSOM.
Dans cet arbre, seul les éléments visibles sont présents. Par exemple les balises styles, meta n’apparaissent pas.
A partir du DOM et du CSSOM déterminé plutôt, voici le nouvel arbre obtenu.
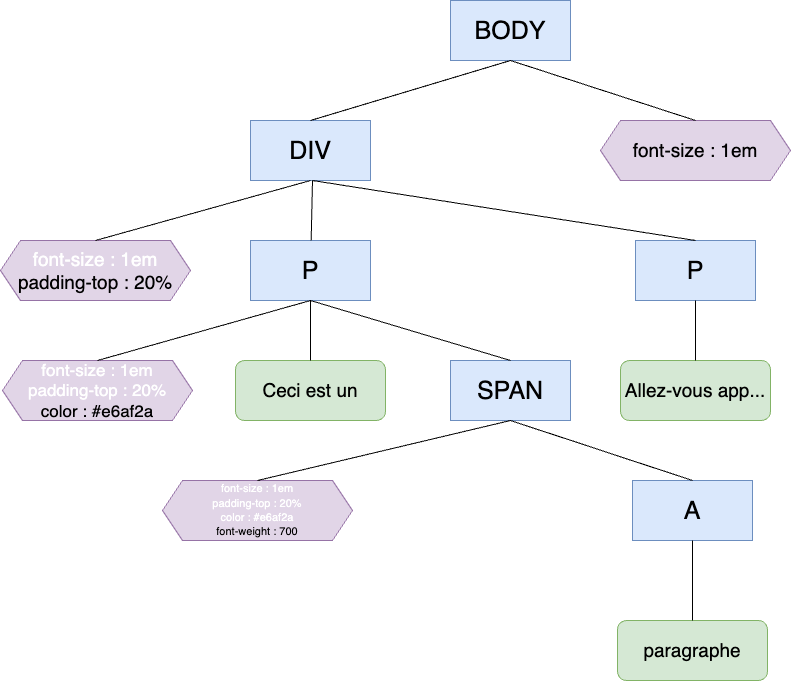
A partir cet arbre, le navigateur va calculer la taille et l’emplacement de chaque élément appelée ici « boîtes ».
Peinture
Le navigateur doit déterminer où chaque élément doit se placer au sein du navigateur de l’utilisateur. Il doit donc identifier le rôle de chaque pixel sur l’écran. On appelle cela la rastérisation.
Certains éléments vont se chevaucher. Il faut donc déterminer lequel se trouve devant et lequel se trouve derrière. Cette phase réalisera ces déterminations.
Par exemple, sur Chrome, le thread principal va créer les Paints Records pour spécifier les étapes à faire pour rendre correctement la page.
Si des éléments de style sont changés à la volée grâce à une animation, la phase de Disposition et la phase de Peinture doivent être à chaque fois recalculées. L’animation devient donc très couteuse en ressources.
Composition
J’écris cet article sur un MacBook Air M2. Ce dernier a plus de 4 millions de pixels. La rastérisation se fait donc sur un nombre très important de pixels et doit être faite très rapidement pour n’avoir aucune latence pour l’utilisateur.
Pour gagner en efficacité, le dessin à l’écran va être divisé en couche. Chaque couche va être rasterisée indépendamment. À la place d’utiliser le thread principal, le thread de la Composition entre en jeu. Il va appeler pour chaque couche un Raster Thread qui rastérisera sa couche. Elle sera stockée dans la mémoire du GPU.
Puis, au chargement des couches, le navigateur va composer la page en s’appuyant sur les différentes couches.
Pour des questions d’optimisation, le navigateur rastérise en priorité les couches contenant des éléments visibles immédiatement par l’internaute ou ceux proches de son champ de vision.
Si l’utilisateur scrolle sur son navigateur, les couches sont déjà rasterisées. Ce dernier devra juste composer sa page à partir des couches.
Conclusion
Maintenant que vous êtes arrivés à la fin de ce(s) article(s), vous en savez plus sur le fonctionnement de nos navigateurs et sur leurs fonctionnements.
Si vous voulez aller plus loin, je vous partage ce lien présentant le projet d’Andreas Kling pour créer un nouveau navigateur, LadyBird.
De mon côté, je n’en ai pas fini avec les navigateurs. En travaillant sur ce sujet, l’ingénierie de ces produits m’a captivé et j’ai décidé de me plonger plus en profondeur. Dans un délai très court, je vous exposerai mes travaux dessus. Vous en saurez plus rapidement :).


[…] vous propose dans le prochain article de voir comment un navigateur peut à partir du code reçu du serveur afficher de manière rapide […]
[…] L’ingénierie expliquant leur fonctionnement interne […]